By Greta Suiter, Manuscripts Archivist, Ohio University Libraries. This post is the first of three posts about adding collection information to Wikidata.
Wikidata is the largest linked open data, open knowledge project in the world. There are millions of items in Wikidata. Each item has a Q number to identify it and is described with properties that have P numbers. Items can be made for people, organizations, buildings, books, periodical articles, patents, and even archival and manuscript collections. At OU we are starting to put manuscript collection information into Wikidata in order understand the collections in new ways. This post looks at some of the reasons why we might want to do this and how we are doing it.
Why are we adding collection data to Wikidata?
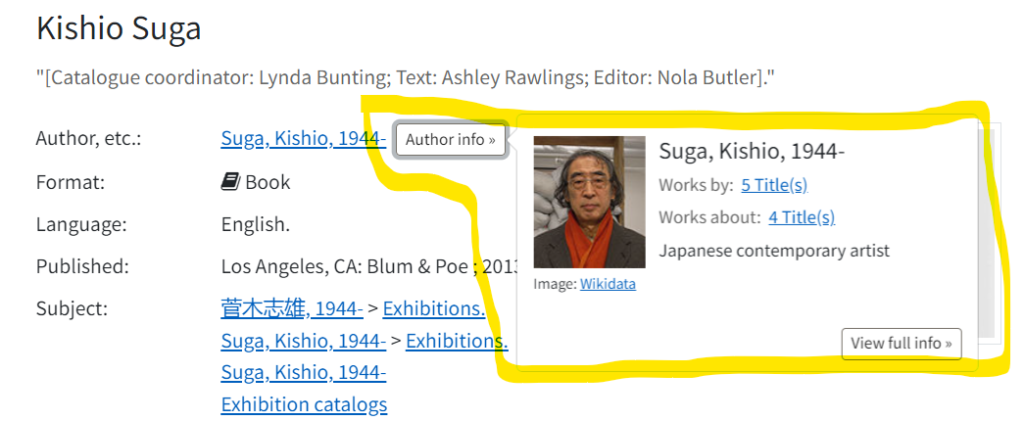
There are many compelling reasons for libraries to add content to Wikidata. My personal hope is that it is beneficial for me to better understand the collections, but also helpful in presenting information about the OU manuscript collections to stakeholders including, researchers, faculty, students, staff, and donors. By utilizing Wikidata we can connect local information to a large, linked data set with thousands of active volunteers also contributing information. By utilizing this open knowledge project, collection Wikidata items or creator Wikidata items have the potential to be used and improved on by a large global audience. With Wikidata we can connect collection items to people and organization items which enhance our understanding and context of collections. Wikidata has also been proven to dramatically increase search engine optimization by providing structured open data for search engines to process efficiently. One can use the SPARQL query service to search across Wikidata and to create dynamic interactive data visualizations. By contributing data to Wikidata we are also building a foundation of data that we can continue to build on in the future. For instance, in the future we could create knowledge panels to be integrated into our local library catalog – Cornell University Libraries has done this. Below is an example from the Cornell Library catalog. When a user clicks on the “author info” button a small panel appears. In this example, the panel pulls in a description and image from Wikidata.
Further Resources
In a recent presentation by Jackie Shieh (available on YouTube) from the 2022 Smithsonian Digitization Conference, Shieh outlines the following reasons cultural heritage institutions might want to use Wikidata:
-
- International structured standards
- Re-use by external services as linked open data
- Rich content representations
- Tables
- Bubble charts
- Interactive graphs
- Timelines
- Maps
- Metrics and maintenance framework
- Evaluating coverage of topic areas
- Correction of mismatches and erroneous description
Read more about adding data to Wikidata on the Wikidata:Data Donation webpage and also check out – “The Power of Parallel Description: Wikidata and Archival Discovery” (part of the Lighting the Way Handbook).
Future blog posts in this series will look at collection creator Wikidata items – for example the Cornelius Ryan Wikidata item – and collection Wikidata items – for instance the Cornelius Ryan Collection of World War II Papers. We will explore how these items are created and how they can be queried. The second post in this series can be found here.